안녕하세요
AX전환팀 우디입니다.
저희팀은 ByOrbit 을 개발함에 있어서, 부산물의 데이터베이스를 정립하고 있습니다.
원물에 대한 성분 데이터부터 부산물 성분데이터와 CoA확보, 그리고 물질의 흐름분석과 산지정보,운송정보 등 원물부터 최종단계까지의 LCA(전체흐름과정)을 확보하고자 노력하고 있습니다. 그러한 단계의 일환으로 첫번째 데이터를 구축하고 있는 부분이 바로 '사과' 입니다.
물질흐름분석을 통한 데이터 베이스 구축
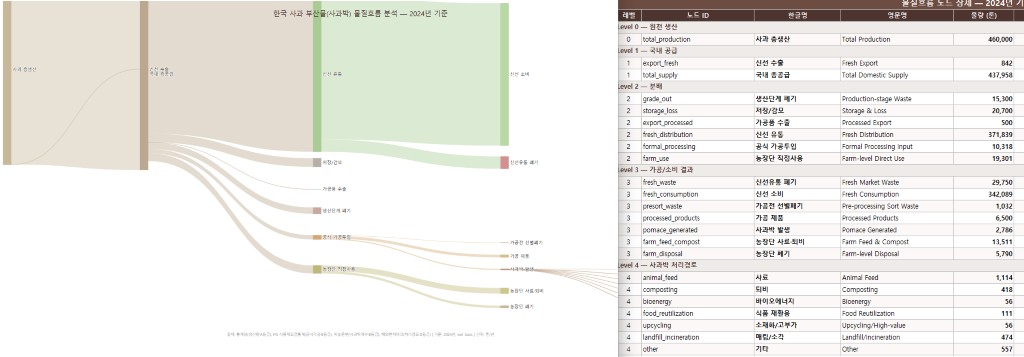
2024년 한국에서 사과 460,000톤이 생산됐습니다. 이 숫자는 통계청이 발표한 공식 수치라 신뢰도가 높습니다.
문제는 그 다음부분 이였습니다. 이 사과들이 유통 과정에서, 가공 과정에서, 농장에서 어떻게 흘러가는지를 추적하면 할수록 데이터가 보이지 않았습니다. 특히 사과박(apple pomace) - 사과주스나 사과 가공품을 만들고 남는 착즙 부산물 부분은 더 심각했습니다. 얼마나 발생하는지, 어떻게 처리되는지, 고부가 활용이 얼마나 이루어지는지에 대한 공식 통계가 사실상 없었습니다.
그 공백을 물질흐름분석(MFA, Material Flow Analysis) 방법론을 통해 시각화하고 데이터화를 해나간 과정입니다.
한국 농식품 부산물 데이터의 현실
UC Davis AIFS의 데이터를 보면 미국·EU는 작물별 부산물 발생량과 처리경로를 체계적으로 추적한다. 사료로 갔는지, 퇴비가 됐는지, 바이오에너지로 전환됐는지까지 수치화되어 있다. (미국역시 이 부분이 걸을마를 뗀 단계로 보여집니다. 이제 4개의 작물에 대해서만 확인이 되고 있기 때문입니다.)
현재 우리나라에서는 사과 가공비율 하나를 찾으려 해도 아래와 같은 문제점들이 확인되고 있습니다.
- 통계청: 생산량·재배면적은 있음. 가공량 없음.
- FIS(식품제조업통계): 사과주스 제조업체 투입량 추적 가능. 단, FIS 기준 공식 가공비율은 2.36% — 총생산 대비 극히 일부.
- 현장: 농장에서 직접 주스를 짜거나 소규모 가공을 하는 비공식 채널이 상당수 존재하나 통계에 잡히지 않음.
---
2-Tier 모델: 데이터 갭을 구조로 풀기
단일 가공비율 하나를 억지로 맞추는 대신, 가공 경로를 두 층으로 분리했습니다.
총 공급 374,770t
├── 공식가공 (Formal Processing) 8,845t ← FIS 실측 B등급
└── 농장단 직접사용 (Farm-level) 12,452t ← 잔차 추정 D등급
공식가공은 FIS 식품제조업통계에서 추적 가능한 주스·통조림 제조업체 투입량으로. 신뢰도 B등급. 농장단 직접사용은 "총공급에서 신선유통·공식가공·손실을 뺀 나머지"로 계산. 신뢰도 D등급. 데이터가 없다는 사실 자체를 모델 구조에 명시적으로 담았습니다.
---
어떤 기준으로 계산했을까?
사과박 계산: Q_bp = Q_in × (1 - Y - l)
공식가공 투입량(8,845t)에서 사과박이 얼마나 나오는지는 학술문헌 4건의 평균으로 계산했습니다. 착즙 수율(Y) = 70% (주스 + 농축액)
가공 중 손실(l) = 2% (세척수·기타)
사과박 비율 = 1 - 0.70 - 0.02 = 28% ≈ 30% (wet basis)
사과박 발생량 = 7,961t × 0.30 = 2,388t
범위는 1,300t ~ 3,700t. 점추정치 하나가 아니라 [min, max]와 함께 저장됩니다.불확실성이 있다는 것을 숨기기보다는 실제 데이터를 통해 이 부분을 고도화해나갈 계획입니다.
---
massflow 데이터 모델 설계
1. 모든 수치에 신뢰도 등급을 붙인다
{
"id": "pomace_generated",
"value": 2388,
"range": [1300, 3700],
"source_reliability": "B"
}A(공식통계) / B(준공식) / C(업계벤치마크) / D(추정치). 차트를 보는 사람이 어떤 기준으로 정리된 것인지 확인 할 수 있도록 했습니다. 시각화 코드는 massflow.json만 읽으면 되도록 했습니다.
2. 연도를 교체하면 전체 파이프라인이 재실행됩니다.
동일한 코드를 공유하도록 설계하여 물질흐름을 확인하기 쉽게 만들었습니다. 예를들어 생산량 460,000t(2024)을 넣으면 사과박 2,786t, 신선유통 폐기 29,750t이 자동으로 계산되게 됩니다. 이 부분은 각 작목별도 별도의 데이터와 서식이 필요한 부분입니다. 이 부분들도 최대한 데이터를 확보하여 신뢰도를 높이고자 하고 있습니다.
레이아웃 원칙은 샘플 차트(UC Davis AIFS 스타일)에서 참고했습니다.
- 총생산 → 국내공급 → 신선유통 → 신선소비가 상단 수평 밴드를 형성
- 손실(저장감모, 생산단계폐기), 가공, 농장단이 아래로 분기
- 사과박 처리경로 7개가 우측 하단에서 부채꼴 형태로 펼쳐짐
---
결과물: 데이터 공백을 드러내는 차트
완성된 차트를 보면 두 가지가 눈에 들어오게 됩니다.
첫째, 신선 소비가 압도적으로 크다. 한국 사과의 80% 가까이가 신선 과일로 소비된다. 사과박 2,388t은 전체 394,000t의 0.6%에 불과하다는 부분입니다.
둘째, 사과박 처리경로는 대부분 주황색(D등급)이다. 사료 40%, 퇴비 15%, 매립·소각 17%, 기타 20%. 이 데이터는 모두 유럽·미국 벤치마크를 한국에 그대로 적용한 추정치 입니다. 한국 현장 데이터 가 없기 때문에 그것을 함께 확보해나가고 있는 상태입니다.
이 프로젝트의 목적은 "명확한 것과 불명확한 것" 을 시각적으로 명확하게 표현하고. 인터뷰와 실측조사가 필요한 노드가 어디인지 한눈에 보이게 하고자 했습니다.
---
다음 단계
차트와 Excel 데이터시트(신뢰도·출처 포함)를 가지고 사과가공업체 인터뷰를 진행할 예정입니다. D등급 노드들이 B등급으로 신뢰도를 높이기 위함입니다. 이미 일부 데이터는 반영한 상태이긴 하지만, 경북 이외에 최대한 많은 데이터를 확보하여 더 신뢰도를 높이고자 노력하고 있습니다.
앞으로 같은 파이프라인으로 다른 식품부산물로 확장하는 것도 계획 중 입니다.
감사합니다.
